Thema: Künstliche Intelligenz
Grafik: Sina Gösele
23.03.2026 | Katrin Schröder
KI-Werkstatt: KI in der Hochschullehre
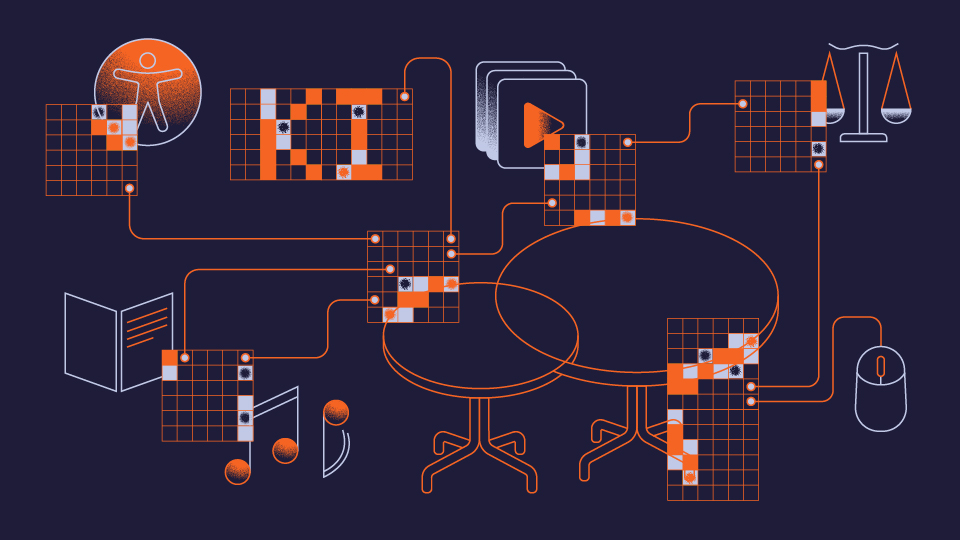
Unter dem Titel “KI in der Hochschullehre – Perspektiven, Praxis und Austausch” veranstalten wir am Donnerstag, 4. Juni von 14:00–17:15 Uhr eine KI-Werkstatt. Diese findet in Präsenz im Forum Finkenau der HAW Hamburg statt. Die Teilnahme ist kostenfrei, eine Anmeldung über das untenstehende Formular ist aus organisatorischen Gründen erforderlich.
Generative KI verändert die Hochschullehre rasant – von neuen didaktischen Möglichkeiten über rechtliche Fragen bis hin zu Herausforderungen für Prüfungen, Inklusion und Medienproduktion. Doch wie können Lehrende und Hochschulen diese Entwicklungen sinnvoll und verantwortungsvoll gestalten?
In der KI-Werkstatt, die vom Multimedia Kontor Hamburg (MMKH) in Zusammenarbeit mit der HAW Hamburg und in Partnerschaft mit der Hamburg Open Online University organisiert und durchgeführt wird, erwarten Sie eine Keynote von Jonas Leschke (HAW Hamburg) sowie mehrere interaktive Thementische. Dort diskutieren wir gemeinsam aktuelle Fragen rund um den Einsatz von KI in Studium und Lehre, etwa zu neuen Aufgabenformaten, rechtlichen Rahmenbedingungen, Inklusion, Unterstützungsstrukturen oder kreativen Anwendungen wie Musik und Medienproduktion.
Die Veranstaltung bietet Raum für Austausch, Perspektivenvielfalt und praxisnahe Impulse. Bringen Sie Ihre Erfahrungen, Fragen und Ideen ein und gestalten Sie gemeinsam mit anderen Teilnehmenden die Zukunft der KI-gestützten Hochschullehre.
Zielgruppe
Die KI-Werkstatt richtet sich vor allem an Hochschullehrende sowie Kolleg*innen aus Service- und Supporteinrichtungen der Hochschullehre an den Hamburger Hochschulen. Zudem sind interessierte Bürgerinnen und Bürger aus Hamburg herzlich eingeladen. Wir freuen uns über Ihr Interesse und Ihre Mitwirkung bei der Erschließung unterschiedlicher KI-Anwendungsbereiche.
Programmablauf
- 14:00 Begrüßung
- Keynote Jonas Leschke, Leitung Zentrum für Lehren und Lernen, HAW Hamburg: “Lehren und Lernen trotz generativer KI”
Die Potenziale und Herausforderungen generativer KI für das Lehren und Lernen an Hochschulen werden intensiv diskutiert. Doch in welchem Verhältnis stehen heute Lernprodukt, Lernhandlung und intendierter Lernprozess? Welche konkreten didaktischen Konsequenzen ergeben sich daraus für die Praxis für Lehrende und Studierende? Im Vortrag werden verschiedene etablierte pädagogisch-psychologische Modelle im Kontext generativer KI diskutiert und praxisnahe Implikationen für die Gestaltung von Hochschullehre sowie für die Weiterentwicklung der Kompetenzen von Lehrenden und Studierenden abgeleitet.
- Keynote Jonas Leschke, Leitung Zentrum für Lehren und Lernen, HAW Hamburg: “Lehren und Lernen trotz generativer KI”
- 14:45–15:45 Erste Tischrunde
- 15:45–16:15 Pause
- 16:15–17:15 Zweite Tischrunde
- 17:15 Verabschiedung
Unsere Thementische
Aufgabenformate für den verantwortungsvollen KI-Einsatz gestalten
Leitung: Dr. Sophie Heins und Franz Vergöhl (beide HCU Hamburg)
Inhalt: Wir stellen die Ergebnisse einer im Jahr 2025 durchgeführten Delphi-Studie vor. Gegenstand der Studie war die Frage, wie Aufgaben und Hinweise zur Nutzung von KI gestaltet sein sollten, damit Studierende weiterhin möglichst eigenständig arbeiten.
KI in Lehre und Studium – Wie gehe ich möglichst rechtssicher vor?
Leitung: Andrea Schlotfeldt (HAW Hamburg), Jens O. Brelle (Multimedia Kontor Hamburg)
Inhalt: Der Thementisch beleuchtet in Impulsvorträgen aktuelle Entwicklungen und Gerichtsentscheidungen rund um urheber- und datenschutzrechtliche Bezüge beim Einsatz von KI-Anwendungen in Lehre und Studium sowie auch rechtliche Aspekte beim Einsatz von KI in Prüfungen. Anschließend besteht die Gelegenheit für Austausch und Fragen.
KI & Inklusion – KI als Treiber oder Hindernis für eine inklusive und gerechte Bildung? Neue Perspektiven auf ein komplexes Thema
Leitung: Katrin Bock (TU Hamburg)
Inhalt: Der Einsatz von KI könnte neuen Schwung in unser Bildungssystem bringen und dringend benötigte Verbesserungen ermöglichen. Doch profitieren wirklich alle Lernenden im Sinne einer inklusiven und chancengerechten Bildung davon? Um dies besser zu verstehen, braucht es eine Klärung grundlegender Fragen, die Berücksichtigung verschiedener Blickwinkel und praktische Lösungen. So lassen sich Probleme schnell angehen und Potenziale bestmöglich nutzen. Der Thementisch liefert einen kurzen Überblick über dieses komplexe Thema. Gemeinsam sollen Fragen diskutiert, geklärt oder auch neu gestellt werden.
KI-Einsatzszenarien & Unterstützungsstrukturen
Leitung: Louisa Zwenger und Johannes Schäfers (beide TU Hamburg)
Inhalt: Wie kann KI die Lehre an Hamburger Hochschulen unterstützen? An unserem Thementisch „KI-Einsatzszenarien & Unterstützungsstrukturen“ wollen wir euch einen Einblick in ein innovatives Lernraumkonzept – am Beispiel der TUHH – aufzeigen. Gemeinsam entwickeln wir Visionen für unsere Hochschulstandorte, diskutieren Best Practices und sammeln im Plenum konkrete Wünsche für eine zukunftsfähige Lehre. Kommt vorbei, bringt eure Ideen ein und gestaltet mit uns die KI-gestützte Lehre von morgen!
Wenn Bewegung Musik wird – KI zum Anfassen und Hören
Referentin: Xiao Fu (HFMT Hamburg)
In diesem Beitrag geht es darum, wie Künstliche Intelligenz Musik nicht nur erzeugen, sondern auch auf menschliche Bewegung reagieren kann. Am Beispiel eines interaktiven Systems wird gezeigt, wie Gesten eines gehörlosen Performers in Echtzeit in Klang übersetzt werden. Dabei kommen sowohl regelbasierte als auch lernende Verfahren zum Einsatz, die gemeinsam eine flexible und zugleich stabile musikalische Struktur ermöglichen. So entsteht ein Raum, in dem Musik, Körper und Technologie unmittelbar miteinander verbunden sind. Gleichzeitig stellt sich die Frage: Wer steuert hier eigentlich wen – der Mensch die Maschine oder umgekehrt
Prompt. Generate. Play. Let’s generate Videos!
Leitung: Jan von Roth, Christoph Dobbitsch, Philippe Schaumburg (Multimedia Kontor Hamburg)
Inhalt: Wie sieht die Zukunft der Videoproduktion aus? An unserem Thementisch experimentieren wir mit aktuellen KI-Tools zur Videogenerierung und erkunden, wie sich Videoinhalte künftig mithilfe generativer KI erstellen lassen.
Gemeinsam produzieren wir kurze Clips, in denen historische Persönlichkeiten als KI-Avatare zum Leben erweckt werden und ihre Geschichten erzählen. Sprache, Bilder und Videos entstehen dabei allein durch Texteingaben.
Nach einem kurzen theoretischen Einstieg probieren die Teilnehmenden die Technologien selbst aus und entwickeln eigene Videos mit KI-gestützten Produktionsworkflows.
Anmeldung
Die KI-Werkstatt „KI in der Hochschullehre – Perspektiven, Praxis und Austausch“ findet in Präsenz im Forum Finkenau der HAW Hamburg statt. Die Teilnahme ist kostenfrei, eine Anmeldung über das MMKH ist aus organisatorischen Gründen erforderlich.

26.02.2026 | Christian Friedrich
LLMs angreifen! OWASP’s Top 10



LLM Verwundbarkeiten und deren Absicherung: Wir besprechen die OWASP Top 10!
Eigentlich ist das Open Web Application Security Projects (OWASP) als amerikanische NGO international im Bereich von Web-Anwendungen und deren Sicherheit unterwegs. Da LLMs mit ihrer Bedienung, Verfügbarkeit und Lernbasis aber auch irgendwie im Web anzusiedeln sind, hat OWASP ein Projekt, das sich um LLM-Verwundbarkeiten und deren Absicherung kümmert. An dieser Dokumentation in der Version 2025 vom 18. Nov. 2024 orientieren wir uns im Gespräch heute. Und wir verlinken sie euch in den Shownotes.
Links
OWASP Top 10 for LLM Applications 2025
Unsere Folge zur (Un-)Sicherheit von LLMs, insbesondere in Sicherheitsbehörden
Podcast App Empfehlungen
Unsere Kapitelbilder könnt ihr mit einer guten Podcast App sehen. Zum Beispiel mit:
Die Sicherheits_lücke im Netz
Abonniere Die Sicherheits_lücke überall, wo es Podcasts gibt, oder über unsere Website: https://www.sicherheitsluecke.fm
Die Sicherheits_lücke bei Mastodon
Die Sicherheits_lücke bei LinkedIn
Die Sicherheits_lücke bei Pixelfed
Feedback oder Kritik? Wünsche? Schreib uns: post@sicherheitsluecke.fm
Die Sicherheits_lücke ist ein Podcast der Hamburg Open Online University (HOOU).
Monina Schwarz, LSI Bayern
Volker Skwarek an der HAW Hamburg
Produktion und Musik: Christian Friedrich
Das in dieser Episode verwendete Bildmaterial steht unter der Lizenz CC-BY 4.0, Urheberin ist Anne Vogt.

29.01.2026 | Christian Friedrich
(Un-)sicher mit LLMs?

Untertitel
Zu Gast: Dr. Tobias Wirth, Leiter des Transferlabors Innere Sicherheit am DFKI
Beschreibung
Mit Tobias Wirth haben wir über die (Un-)Sicherheit von LLMs und KI Anwendungen in Sicherheitsbehörden gesprochen. Er ist Themenfeldleiter für generative und transparente KI im Forschungsbereich smarte Daten- und Wissensdienste am DFKI und leitet das Transferlabor KI-Forschung für die Polizei KI4POL.
Im Gespräch geht es um Möglichkeiten, LLMs auszutricksen, darum, wie Sicherheitsbehörden sich gegen die größten Angriffsvektoren schützen können und darum, was wir daraus auch auf den Alltag außerhalb von Sicherheitsbehörden lernen können.
Links
BSI-Publikationen
BSI: Generative KI-Modelle – Chancen und Risiken für Industrie und Behörden (PDF)
BSI: Evasion-Angriffe auf LLMs – Gegenmaßnahmen (PDF)
Sicherheit und Schwachstellen
Malwarebytes: ChatGPT Deep Research Zero-Click Vulnerability
OWASP Top 10 for Large Language Model Applications
Agentic LLM Vulnerabilities (arXiv, Stanford HAI)
Tools und Ressourcen
GARAK – LLM Vulnerability Scanner
Prompt Injection in the Wild (Kaggle Dataset)
Podcast App Empfehlungen
Unsere Kapitelbilder könnt ihr mit einer guten Podcast App sehen. Zum Beispiel mit:
Die Sicherheits_lücke im Netz
Abonniere Die Sicherheits_lücke überall, wo es Podcasts gibt, oder über unsere Website: https://www.sicherheitsluecke.fm
Die Sicherheits_lücke bei Mastodon
Die Sicherheits_lücke bei LinkedIn
Die Sicherheits_lücke bei Pixelfed
Feedback oder Kritik? Wünsche? Schreib uns: post@sicherheitsluecke.fm
Die Sicherheits_lücke ist ein Podcast der Hamburg Open Online University (HOOU).
Monina Schwarz, LSI Bayern
Volker Skwarek an der HAW Hamburg
Produktion und Musik: Christian Friedrich
Das in dieser Episode verwendete Bildmaterial steht unter der Lizenz CC-BY 4.0, Urheberin ist Anne Vogt.

Bild: Midjourney
23.01.2026 | Katrin Schröder
Lunch Bag Session: KI-Bilderwelten! Einführung in Bildgeneratoren
In dieser Online-Schulung bieten wir am 6. Mai, 12 bis 13 Uhr einen Überblick über die bekanntesten Text-zu-Bild KI-Generatoren und deren vielfältige Anwendungsmöglichkeiten. Diese 60-minütige Schulung richtet sich an alle Interessierten, unabhängig von Vorkenntnissen, und lädt dazu ein, die faszinierende Welt der künstlichen Intelligenz zu entdecken und zu verstehen, wie sie kreative Prozesse unterstützen kann.
Die Schulung beginnt mit einer kurzen Einführung in die grundlegenden Konzepte von KI-Bildgeneratoren. Es wird gezeigt, wie diese Technologien funktionieren und welche technischen Voraussetzungen notwendig sind. Im Anschluss daran werden die bekanntesten und am weitesten verbreiteten Text-zu-Bild KI-Generatoren (beispielsweise Midjourney, Leonardo.AI, ChatGPT) live vorgestellt, einschließlich ihrer spezifischen Funktionen, Herausforderungen und Anwendungsbereiche.
Für die Teilnahme an dieser Schulung sind keine Vorkenntnisse erforderlich. Alle, die sich für die Möglichkeiten und Herausforderungen der künstlichen Intelligenz interessiert, ist herzlich eingeladen, teilzunehmen. Weitere Informationen zu KI-Anwendungen gibt es auch im kostenfreien HOOU-Kurs „KI-Tools kurz erklärt! So verwendest du ChatGPT, Leonardo.AI & Co.“
Melden Sie sich jetzt über unseren HOOU-Partner, das Multimedia Kontor Hamburg, an und lassen Sie uns gemeinsam die kreativen Potenziale von KI-Bildgeneratoren entdecken.
ZUR ANMELDUNG
Die Lunch Bag Session wird vom Multimedia Kontor Hamburg (MMKH) in Zusammenarbeit mit der Hamburg Open Online University (HOOU) organisiert und durchgeführt.

Foto: KI-generiert
23.01.2026 | Katrin Schröder
Lunch Bag Session: Einführung in KI-Textgeneratoren
Unter dem Titel „Lunch Bag Session: Einführung in KI-Textgeneratoren“ veranstalten wir für alle Interessierten am Mittwoch, 25. März von 12 bis 13 Uhr eine Lunch Bag Session. Diese findet auf ZOOM statt. Die Teilnahme ist kostenfrei, eine Anmeldung ist aus organisatorischen Gründen erforderlich.
In dieser Online-Schulung wird ein Überblick über die Möglichkeiten von KI-Tools, wie beispielsweise ChatGPT, Claude und Gemini gegeben. Die Schulung richtet sich an alle Interessierten – nicht nur aus dem Hochschulbereich, sondern auch explizit an interessierte Bürger*innen – unabhängig von Vorkenntnissen, und vermittelt ein grundlegendes Verständnis für die Anwendungen und Potenziale dieser KI-Modelle.
Die Schulung beginnt mit einer Einführung in die Grundlagen von KI-Sprachmodellen, die Texte erstellen, übersetzen und umschreiben können, aber auch dichten, programmieren und unterstützen. Es wird gezeigt, wie die Anwendungen funktionieren und welche Einsatzmöglichkeiten sie bieten.
Weitere Informationen zu KI-Anwendungen gibt es auch im kostenfreien HOOU-Kurs „KI-Tools kurz erklärt! So verwendest du ChatGPT, Leonardo.AI & Co.“
Jetzt bei unserem HOOU Partner MMKH Hamburg kostenfrei anmelden: ZUR ANMELDUNG
Die Lunch Bag Session wird vom Multimedia Kontor Hamburg (MMKH) in Zusammenarbeit mit der Hamburg Open Online University (HOOU) organisiert und durchgeführt.

28.12.2025 | Christian Friedrich
Live vom 39C3 - Tag 1

Die Sicherheits_lücke live aus dem Sendezentrum beim 39C3 – Tag 1
Wir senden in diesem Jahr jeden Tag live vom 39C3, dem 39. Chaos Communication Congress in Hamburg. In dieser Folge sprechen wir auf der Bühne des Sendezentrums über die Vorträge von Tag 1, die wir empfehlen möchten, und darüber, weshalb wir sie interessant und relevant finden. In dieser Folge zu Gast sind Marieke, Petersen, Elena Müller und Karola Köpferl.
In dieser besonderen Live-Episode senden wir direkt vom 39. Chaos Communication Congress in Hamburg. Auf der Bühne des Sendezentrums sprechen wir mit unseren Gästinnen Marieke Petersen, Elena Müller und Karola Köpferl über die Vorträge des ersten Congress-Tages.
Wir diskutieren, welche Talks uns besonders beeindruckt haben und warum sie relevant für die Cybersicherheits-Community sind – von politischen Aktionen über forensische Technologien in Ausländerbehörden bis hin zu KI in der Medizinentwicklung und kreativen Hardware-Hacks.
Website: www.sicherheitsluecke.fm
LinkedIn: https://www.linkedin.com/company/die-sicherheitslücke/
Mastodon: https://podcasts.social/@DieSicherheits_luecke
Links zu dieser Folge
39C3 Mediathek – Alle Vorträge
Zentrum für Politische Schönheit: Ein Jahr Adenauer, SRP und mehr
Handy weg bis zur Ausreise: Wie Cellebrite ins Ausländeramt kam
Developing new Medicines in the Age of AI and Personalized Medicine
Not an Impasse: Child Safety, Privacy, and Healing Together
KI, Digitalisierung und Longevity als Fix für ein kaputtes Gesundheitssystem
FetAp 611 unplugged: Taking a rotary dial phone to the mobile age
Podcast App Empfehlungen
Unsere Kapitelbilder könnt ihr mit einer guten Podcast App sehen. Zum Beispiel mit:
Die Sicherheits_lücke im Netz
Abonniere Die Sicherheits_lücke überall, wo es Podcasts gibt, oder über unsere Website: https://www.sicherheitsluecke.fm
Die Sicherheits_lücke bei Mastodon
Die Sicherheits_lücke bei LinkedIn
Die Sicherheits_lücke bei Pixelfed
Feedback oder Kritik? Wünsche? Schreib uns: post@sicherheitsluecke.fm
Die Sicherheits_lücke ist ein Podcast der Hamburg Open Online University (HOOU).
Credits
Gästinnen:
Elena Müller
Moderation und Produktion:
Volker Skwarek an der HAW Hamburg
Produktion und Musik: Christian Friedrich
Das in dieser Episode verwendete Bildmaterial steht unter der Lizenz CC-BY 4.0, Urheberin ist Anne Vogt.

18.12.2025 | Christian Friedrich
Brandbeschleuniger KI?

Ist KI der Brandbeschleuniger in der Cybersicherheit? Wir sprechen über (vermeintliche) Angriffe mit KI-Systemen und darüber, was wir aus ihnen lernen können.
Ist KI der Brandbeschleuniger in der Cybersicherheit? Wir sprechen über (vermeintliche) Angriffe mit KI-Systemen und darüber, was wir aus ihnen lernen können.
Links zu dieser Folge
Anthropic: Disrupting the First Reported AI-Orchestrated Cyber-Espionage Campaign
BleepingComputer: Anthropic Claims of Claude AI-Automated Cyberattacks Met with Doubt
The Hacker News: Chinese Hackers Use Anthropic’s AI to Launch Automated Cyber Espionage Campaign
Heise: Autonome KI-Cyberattacke: Hat sie wirklich so stattgefunden?
EU AI Act Explorer – Article 15: Accuracy, Robustness and Cybersecurity
OpenAI: Attacking Machine Learning with Adversarial Examples
Wikipedia: Adversarial Machine Learning
IEEE: Explainable AI in Cybersecurity – A Comprehensive Framework
Cybersecurity Tribe: An Introduction to Agentic AI in Cybersecurity
Podcast App Empfehlungen
Unsere Kapitelbilder könnt ihr mit einer guten Podcast App sehen. Zum Beispiel mit:
Die Sicherheits_lücke im Netz
Abonniere Die Sicherheits_lücke überall, wo es Podcasts gibt, oder über unsere Website: https://www.sicherheitsluecke.fm
Die Sicherheits_lücke bei Mastodon
Die Sicherheits_lücke bei LinkedIn
Die Sicherheits_lücke bei Pixelfed
Feedback oder Kritik? Wünsche? Schreib uns: post@sicherheitsluecke.fm
Die Sicherheits_lücke ist ein Podcast der Hamburg Open Online University (HOOU).
Monina Schwarz, LSI Bayern
Volker Skwarek an der HAW Hamburg
Produktion und Musik: Christian Friedrich
Das in dieser Episode verwendete Bildmaterial steht unter der Lizenz CC-BY 4.0, Urheberin ist Anne Vogt.

09.12.2025 | Christian Friedrich
Zamina Ahmad


Gründerin und Beraterin Zamina Ahmad im Gespräch mit Christian Friedrich über faire und verantwortungsvolle KI
Zamina Ahmad ist Expertin für maschinelles Lernen und hilft Unternehmen, KI Anwendungen sinnvoll einzusetzen. Sie setzt sich für Faire KI ein und in dieser Folge geht es auch darum, was das für sie und andere bedeuten kann.
Zamina hat ein Beratungsunternehmen gegründet, dass sich mit Fragen rund um Fairness und Ethik von KI-Anwendungen befasst. Sie hat einen eigenen Podcast, hält regelmäßig Vorträge, gibt Workshops zum Thema KI und ihrem verantwortungsbewusster Einsatz in Organisationen und in Unternehmen. Im Gespräch teilt Zamina auch Tipps, was einzelne Nutzende in ihrer privaten Nutzung von Chatbots wie ChatGPT tun können, um Vorurteile, Stereotypen und vielleicht auch unerwünschte Ergebnisse ein Stück weit zu minimieren.
Links
Programmiersprache Python (Wikipedia)
Zaminas Buchempfehlung: Bas Kast, Wie der Bauch dem Kopf beim Denken hilft
Fair Tech, Fair Society (Podcast)
HOOU Lernangebote
Credits
Moderation: Nicola Wessinghage und Christian Friedrich
Musik: Jakob Kopczynski
Produktion: Christian Friedrich
Die Angebote zum Selbstlernen auf der Online-Plattform der Hamburg Open Online University stehen allen Interessierten frei zur Verfügung.
Um unsere Lernangebote zu nutzen, brauchst du weder zu studieren noch bestimmte Voraussetzungen zu erfüllen. Schau einfach online vorbei. Unsere Internetadresse ist www.hoou.de
Feedback, Anregungen und Kommentare zum Podcast erreichen uns per E-Mail unter waswillstduwissen@haw-hamburg.de

Bild: Maximilian Glas)
09.05.2025 | Katrin Schröder
Online-Workshop für Schüler:innen – „Schreiben und Bilder erstellen mit KI“
Für alle, die lieber online teilnehmen möchten, bieten wir einen Workshop an, bei dem du bequem von zu Hause aus lernen kannst, wie du mit Künstlicher Intelligenz deine Geschichten schreibst und sie visuell zum Leben erweckst. In diesem Workshop wirst du die Grundlagen von KI kennenlernen, eine Geschichte mit der KI entwickeln und dazu passende Bilder generieren. Am Ende des Workshops wirst du nicht nur mit einer Geschichte und einem Bild, sondern auch mit einem neuen Verständnis für die Möglichkeiten der KI aufwarten können.
Diese Workshops werden von der HOOU@HAW Hamburg in Kooperation mit dem SFZ Hamburg durchgeführt und von J&K realisiert. Weitere Informationen findest du auf den offiziellen Webseiten:

09.05.2025 | Katrin Schröder
Eltern-Workshop parallel vor Ort – „KI verstehen und kreativ nutzen“
Dieser Workshop bietet Eltern einen spannenden Einblick in die Welt der Künstlichen Intelligenz und ihre Anwendung im kreativen Bereich. Während die Kinder in einem separaten Workshop mit KI Geschichten schreiben, können die Eltern lernen, wie sie ihren Kindern beim sicheren Umgang mit dieser Technologie zur Seite stehen können. Gemeinsam entdecken wir, wie KI beim Schreiben und der kreativen Gestaltung helfen kann – und welche Lernmöglichkeiten es dafür gibt.
Damit Sie direkt mitmachen können, bringen Sie bitte ein eigenes Gerät (Laptop oder Tablet) mit – das WLAN des SFZ Hamburg steht Ihnen während des Workshops zur Verfügung.
Diese Workshops werden von der HOOU@HAW Hamburg in Kooperation mit dem SFZ Hamburg durchgeführt und von J&K realisiert. Weitere Informationen findest du auf den offiziellen Webseiten: