07.03.2020 | Katrin Schröder
Announcement of the project "Data Quality Explored" (QuaXP)
Written by Anna Lainé (contact)
Motivation
Did you know that most of the hiring processes in big companies are complemented by some machine learning algorithms, in charge of pre-selecting the best resumes before handing them to a human? (1) That some banks use machine learning to predict whether or not you will be able to reimburse a credit? (2) That most online customer support usually start the interactions with an intelligent agent rather than a human? (3) Because of the vast amount of applications we are confronted to in our daily life, a basic knowledge of data science is essential to understand how decisions are made and what we, as a member of society, can do to maximize the efficiency and minimise the risks of these processes.
That is why public awareness on the field of computer science technology is of great importance, and science enthusiasts should not be the only ones to be informed about these challenges and pitfalls. Education should offer learning opportunities to a broad audience, by creating resources that are understandable with no to little scientific background. With that in mind, we want to design an online course about machine learning that is accessible for everybody, with different levels of difficulty.
Technical content of the course
What is machine learning?
Machine learning describes the study or development of models (algorithms or statistical models) used by a computer to perform a task without explicit instructions. The computer is said to learn from the model, and the outcome or result of the model is the task the computer can perform from the model. The performance of the model represents the accuracy, correctness, or precision of the task performed by the computer, compared to what was expected.
A concrete scenario: say we want to build a model that can predict the weather of tomorrow, given the weather of today.
This particular problem is a classification problem (we want to classify the weather of tomorrow into the classes „sunny“, „rainy“, etc…), and the corresponding class („sunny“, „rainy“) is called a label.
Data from the days before are used and fed into the model, which will learn some pattern from the data: for example, if a day was sunny, the next day has high chances to be also sunny. From the data and the patterns learned, the model will compute some predictions for a particular day, given the current data („As today is a sunny day, tomorrow will be a sunny day.“). These predictions are the result, or the outcome of the model. If the prediction fits the real-world observation (tomorrow is, indeed, a sunny day), the performance of the model is considered good.
How are data used in machine learning?
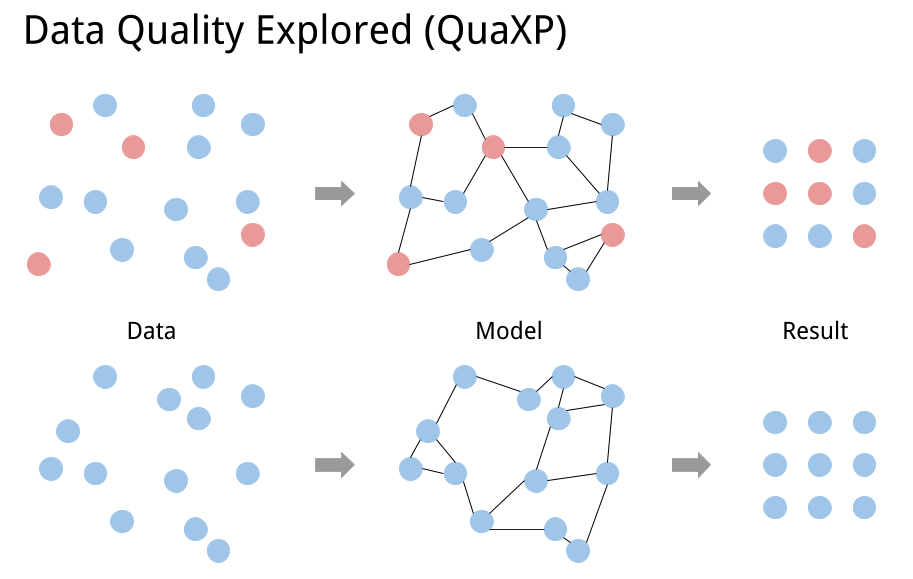
In machine learning projects, the main effort is often focused on building a good model enhanced by the outcome of the learning, rather than on the data it is based on. But using training data of poor quality can also distort this outcome: as the algorithm learns from historical data, by nature, data is the central point of a machine learning model.

A classic machine learning process is built in two main steps (see Figure 1): first, using historical data gathered beforehand, a model is developed and learns to predict the labels from the data. Afterwards, this model is fed with new data for which we don’t know the outcome, and returns predictions.

Data are therefore used in two ways here: first, historical data are used to feed and train the model, then new data are used to make the prediction. If these data are of poor quality, with no surprise, the prediction will be affected. The quality of the data can be affected in several ways, for example:
- incomplete or missing data: some fields of the dataset are left empty (for example: we want to use geographic coordinates of a ship along its trip, but a whole part of the trip is missing).
- incorrect data: some values are wrong in the data (for example: we are using information about the length of a ship, but some values are expressed in meter, others in foot, so the comparison is not directly possible).
- biased data: the training data don’t correspond to the predictive data (for example: we use historical data to predict the estimated time of arrival of a ship on a commercial route, but the historical data are 20 years old and during that time, the traffic in the area doubled: the estimation is incorrect because it is based on data that are not representative of the current situation).
The reasons of these errors can be multiple: lack of understanding, sensor error, transmission error, context error, etc…
Concept of the learning arrangement
The base idea of this project is to raise or sharpen awareness on data quality problems in machine learning, for everyone, with or without prior knowledge in the area of computer science. For that, two levels of difficulty will be implemented:
- „beginner“: requiring neither background in machine learning nor coding skills, the participants of this level will be able to follow a lecture and play with online widgets (with H5P, see following) to assess the consequence of some actions/changes of values on the algorithms.
- „advanced“: targeting learners with basic coding skills. The participants will follow the lecture while working with interactive code cells (in Python, with Jupyter Notebook).
Example of an H5P widget:
Example of a Jupyter Notebook interactive cell (screenshot):

To better combine theoretical knowledge and applications to the real world, the course will be based on examples and data that are used in research. This way, the learner can instantly see and connect what is learned in the course with what is done in the world. For instance, in the first problem the students will have the chance to work on the problem of „trajectory prediction“ of ships, using AIS data (data sent by any ship at sea, containing various information about the location, speed, or status of the ship).
As data quality can vary much depending on the type of data, we chose to focus on 3 different types of data:
- numerical data: data containing mostly numerical values; the simplest type of data to be processed, in this case logistics data (such as AIS data).
- image data: a representation of the pixels constituting an image.
- text data: a harder task for evaluating data quality, where the information is expressed in natural language (sentences).
Each of these 3 types of data constitute a learning block, which ends with a quiz, allowing the learner to check the progress and how much was understood from the lecture. For the advanced level, an additional practical task is proposed, to be solved in Python.
The whole lecture is hosted online, for both the beginner and advanced levels. The students of the advanced level can work with interactive code cells inside the lecture: the language of teaching is Python, as we think it is the most suited language to work with machine learning, given that many open source libraries are available and the language itself is fairly easy to learn.
Context of the project
The project is developed by the Institute for Software Systems (STS) at the TUHH, under the supervision of Prof. Sibylle Schupp.
The STS institute specializes in the following research fields: model checking and abstract interpretation, software quality and verification, and data protection and machine learning.
The collaborators of QuaXP previously worked on a related project: MaLiTuP (Machine Learning in Theory and Practice), a collaboration between the Institute of Maritime Logistics (MLS) and the STS institute, which successfully developed a beginner course in machine learning for students in maritime logistics. With this project, we gained experience in teaching with Python and Jupyter Notebook, as well as in designing lectures and tasks for beginners in machine learning.
Key dates
The development of the 3 learning blocks is expected to take one year. The first part of the course, about numerical data, will be tested and refined with students internally at the TUHH in the summer semester of 2020.
Around October 2020, we expect to have the first two chapters (numerical and image data) openly available online. The last chapter is expected to be finished by the end of the year.
Related links
- „If Your Data Is Bad, Your Machine Learning Tools Are Useless“ by Thomas C. Redman (Harvard Business Review blog): https://hbr.org/2018/04/if-your-data-is-bad-your-machine-learning-tools-are-useless
- „The quest for high-quality data“ by Ihab Ilyas and Ben Lorica: https://www.oreilly.com/radar/the-quest-for-high-quality-data/
- More about AIS data:
- STS institute: https://www.tuhh.de/sts/institute.html
- MaLiTuP project:
- (1) „Machine Learning for Recruiting and Hiring – 6 Current Applications“ by Kumba Sennaar (Emerj): https://emerj.com/ai-sector-overviews/machine-learning-for-recruiting-and-hiring/
- (2) „My Analysis from 50+ papers on the Application of ML in Credit Lending“ by Simeon Kostadinov (towardsdatascience blog): https://towardsdatascience.com/my-analysis-from-50-papers-on-the-application-of-ml-in-credit-lending-b9b810a3f38
- (3) „11 AI Usecases in Customer Service in 2020: In-depth Guide“ (AIMultiple blog): https://blog.aimultiple.com/customer-service-ai/